As a knowledge graph data provider, you would like to maximize the potential of reuse of your data, hence making it accessible to users that don’t necessarily speak the same language as the one used in your dataset.
Typically, cultural heritage data providers want their data to be accessible across Europe and across language barriers. The use-case we encountered was the sharing of cultural heritage data across the Europeana network (in the context of the Europeana Linked Data Taskforce).
Sparnatural, as a tool to promote the content of a knowledge graph, can address this multilingualism concern in order to make the data accessible at large. It does so by combining 2 notions : the user preferred language, and the dataset default language.
Multilingual Sparnatural configuration
To deal with this question of providing a knowledge graph exploration UI in multiple languages, the first and easy thing to do is to configure the entities and properties of Sparnatural in multiple languages. To do this, you simply add more “rdfs:label@xx” and “sh:description@xx” columns in the configuration spreadsheet file for the labels and the tooltips. Adjust the language tag after the « @ », and provide the corresponding translations of your entities, tooltips & properties.
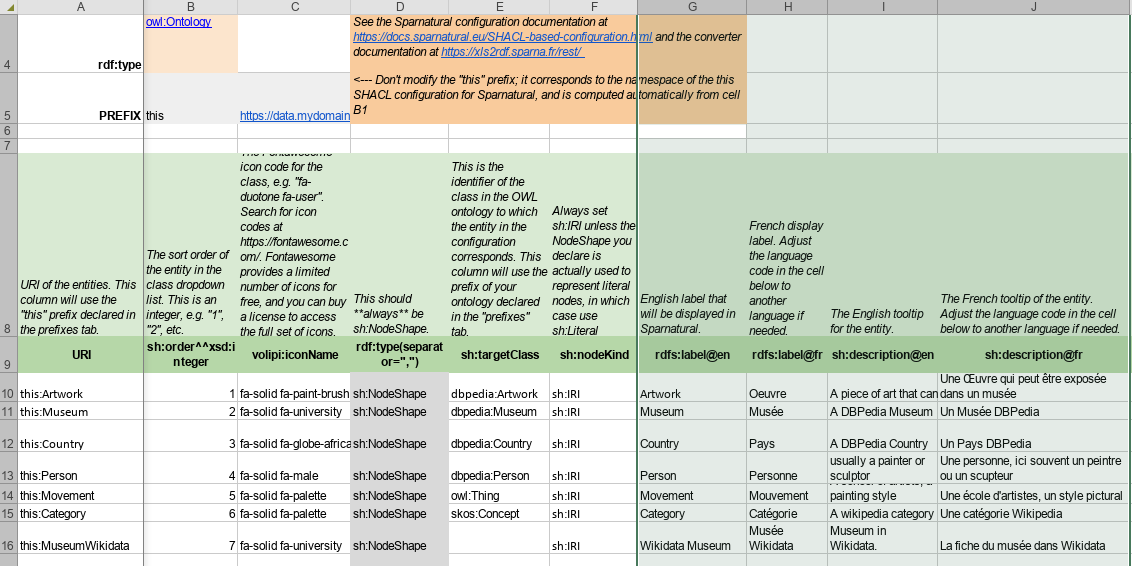
The user language in Sparnatural : « lang » attribute
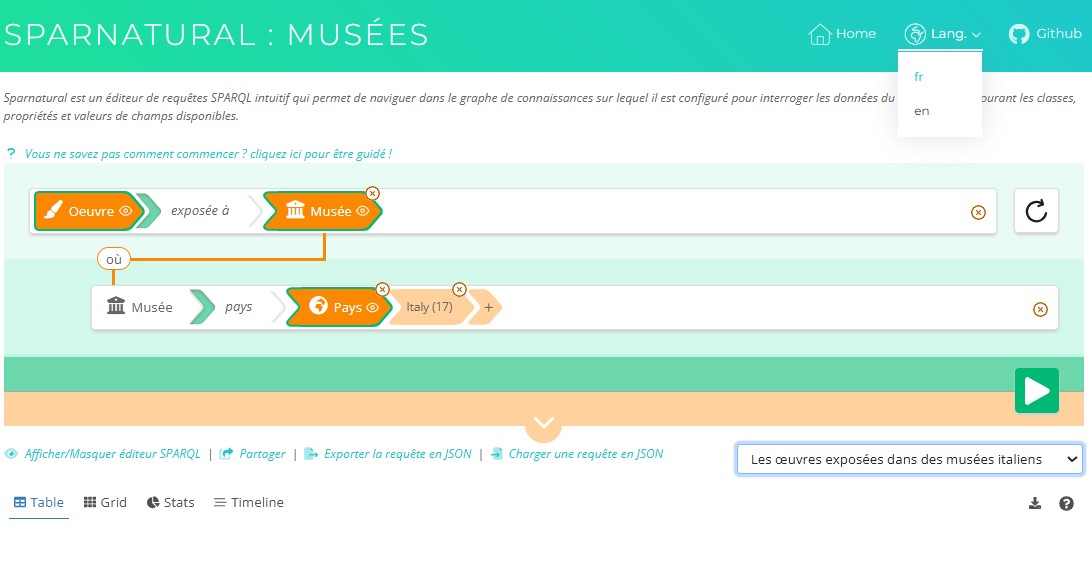
From a multilingual configuration, the labels and tooltips that Sparnatural will pick up depends on the lang attribute of the <spar-natural> element in the HTML page. The « lang » attribute represents the user preferred language.
That attribute is dynamic, meaning that it can be changed from the HTML page, typically from a language selection dropdown : in this case Sparnatural will reload itself with the new language value.
The « lang » attribute, being the user preferred language, will drive :
-
the labels of classes and properties proposed to the user ;
-
the language of the labels that are fetched in value dropdown lists, or that are searched in autocomplete fields ; that parameter is passed as the « lang » variable in datasources queries.
-
the language of the labels that are fetched to populate the query result table (see below).
The dataset default language in Sparnatural : « defaultLang » attribute
Sparnatural also provides a way to specify the default language of the dataset : this is the language in which the knowledge graph is supposed to always have a label for all Entities. This is meant to deal with situations where some Entities do have a label in the user preferred language, and others don’t, but will have a label in a default language. Think of a multilingual taxonomy that would not be 100% translated in every language, but for which the concepts always have a label in this language.
That dataset default language is driven by the « defaultLang » attribute of the <spar-natural> element. Contrary to the « lang » parameter, it is not dynamic : the default language of the dataset does not change [1] ! .
The multilingual default labels in Sparnatural : « dash:LabelRole »
The easy way to display labels in the result table instead of the URIs of the entities is to flag a « human-readable label property » for each type of entity. The human-readable label property will then be fetched automatically in the SPARQL query, and displayed in the query results table. This is done using the dash:propertyRole annotation, with the value dash:LabelRole. Typical human-readable properties are skos:prefLabel, rdfs:label, or schema:name.
The behavior with respect to multilingualism is the following : if the human-readable property has the datatype « rdf:langString », thus indicating a literal with a language tag, then the query will be written in such a way to fetch only the value in « the most appropriate language ».
What is this « most appropriate language » ? it is the user language (the one indicated in the « lang » attribute) but if not found, the default language of the dataset (the one indicated in the « defaultLang » attribute).
SPARQL queries thus look like the following one, where a user reading French tries to query a dataset with default English labels :

Notice the 2 OPTIONAL sections, one to fetch the French label, one to fetch the English label. They are then followed by a « COALESCE » function, that will select the user-preferred-language-label first, and, if not found, the dataset-default-language-label. This ensures that the preference of the user is honored, while always defaulting to an available label.
Multilingualism in Sparnatural datasources
Datasources in Sparnatural is how the value lists and autocomplete search fields are populated. A datasource corresponds to a SPARQL query in which some values are automatically injected. Amongst those values are the « lang » and « defaultLang » parameters, that the datasource SPARQL query can then honor to provide the same behavior as described above in terms of label fetching (get the label in the language most preferred by the user, but if not found, default to a label in a language that is supposed to be always present).
Sparnatural includes a library of predefined datasources, and you can write your own in the configuration (see the corresponding documentation).
Knowledge graphs are rich, but Sparnatural’s configurations are infinite !
And with all these possibilities and multilingual configurations, you can make your knowledge graph friendly again :)
[1] Actually, we made it also a dynamic attribute, to deal with advanced situations where Sparnatural could target different endpoints with a different default language
 ·
·
 ·
·