Isidore, the search engine on humanities and social sciences, indexing more than 7.8 million documents, once had a public SPARQL service, now dead for lack of usage.
Together with the team at the Lab of Huma-Num IR* we resurrected it as the first step of an experiment on the analysis of user journeys in the Isidore portal (funding by Equipex+ Commons). This is actually a half-resurrection, as the new endpoint is not made to be public. And based on this endpoint we can extract meaningful subsets of the metadata through a custom Sparnatural interface.
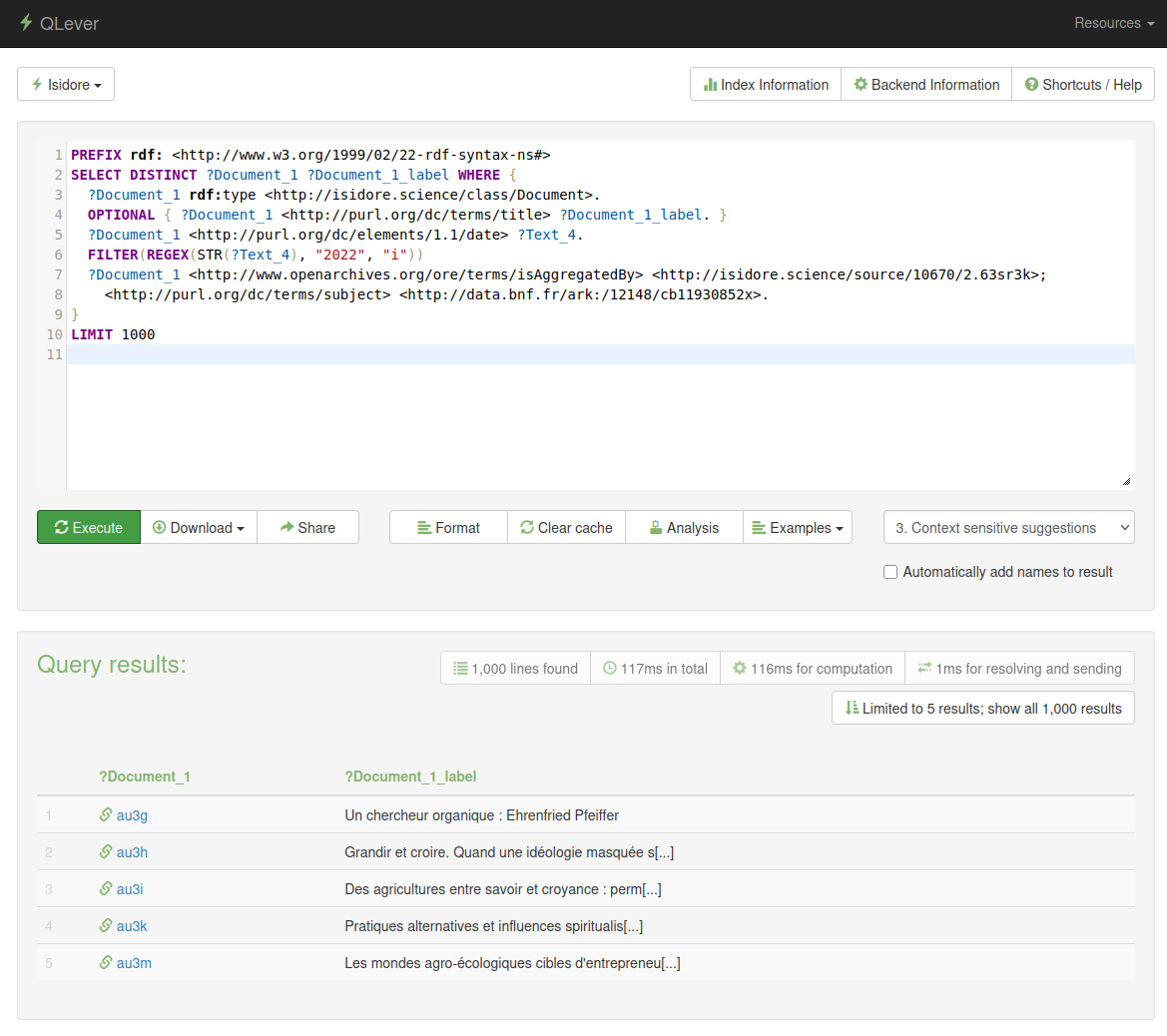
We decided to test QLever to load the full dataset of all documents, sources, collections and authors of Isidore. The dataset is 420 million triples, broken down into 18 million files (!) and the server at our disposal was a medium-size 4 CPU, 32Gb RAM machine. We asked the expertise of our partner of QLeverize, who did an excellent job at deploying Qlever and ingesting the dataset.
QLever ingests the 18 million RDF files in around 2 hours, then we run a serie of SPARQL Update queries to do some data cleaning. Some large updates fail because of a lack of memory, but I would not blame QLever for that as the real source of the problem is in a few syntactic issues in the data files themselves. The queries we are testing are fast, although we haven't benchmarked them against another triplestore. We saw a couple of shortcomings (like the lack of support of the sameTerm function, or the inability in the UI to display datatypes that don't start with http). I think what we are lacking the most right now is a full-text index over some predicates (we were told the full-text index should be here in a few weeks !). This is necessary for us to do some named entity reconciliation for an MCP server as a PoC but ssshhh... this is for another story !

 ·
·
 ·
·